Indledning
Adfærdsgenetik (behavioral genetics) er studiet af genetiske — og dermed også ikke-genetiske — årsager til adfærd, herunder menneskelig adfærd. Der findes en række introduktioner på engelsk, men os bekendt ingen på dansk. Denne side er derfor skrevet som en relativ kort introduktion til emnet. Den er skrevet til intelligente lægmænd som ikke antages at have en stærk baggrund i statistik.
Problemet med genetisk uinformativ forskning
Det meste forskning som laves om mønstre mellem familiemedlemmer er ikke ret informativt. Det skyldes at studierne ikke tager højde for mulige genetiske årsager til adfærd. Forestil dig at vi undersøger relationen mellem forældres og børns højde. Vi opdager at der er en positiv sammenhæng således at høje forældre har det med også at få høje børn. Skyldes det mon at høje forældre giver deres børn god kost så de også vokser sig høje? Eller skyldes det at børnene modtager gener som går en høj fra deres forældre? Måske begge dele? Man kan ikke vide det ud fra den slags data fordi børnene og forældrene har både miljø og gener til fælles. Figuren herunder illustrerer problemet:

Problemet er helt generelt og gælder alle træk man kan undersøge: højde, personlighed, intelligens, BMI/fedme, kriminalitet osv. Man kan ikke vide om lighed mellem børn og forældre skyldes gener, familiemiljø eller en blanding når man ser på relationer mellem børn og deres forældre fordi de har begge dele til fælles.
Genetisk informative data
Den generelle løsning til ovenstående problem er at finde data af en anden type. Tvillinger er særligt velegnede og bruges derfor i høj grad af forskere. Der findes to slags tvillinger: en-æggede (også kaldet ‘identiske’, monozygotic/MZ) og to-æggede (også kaldet tve-æggede, fraternal, dizygotic/DZ). En-æggede tvillinger er kommet til verden ved at et enkelt æg blev befrugtet. Under graviditeten er ægget ved en fejl delt sig til to fostre og derfor kommer der to personer til verden med næsten ens DNA. De eneste forskelle skyldes mutationer som er sket siden delingen, men det er meget få og i praksis taler man om at en-æggede tvillinger er 100% genetisk identiske. (En anden sjælden mulighed er mosaicisme.) To-æggede tvillinger er derimod kommet til verden ved at moderen frigiv 2 æg samtidig som begge blev befrugtet. Genetisk set er de derfor kun lige så genetisk relaterede som normale søskende, dvs. 50%. Det er blot søskende som er lige gamle. (Tallene refererer til hvor ens 2 personers genetik er baseret på nedstamning og har ikke noget at gøre med at mennesker i gennemsnit er mere end 99% genetisk ens.)
I simple studier taler man om tre grupper af årsager til den variation i træk man ser. Disse er arvelighed, delt miljø og udelt miljø (heritability, shared/common environment, unshared environment). Arvelighed refererer til genetiske årsager samlet set. Delt miljø omhandler den slags miljø som søskende har til fælles, særligt den del som stammer fra forældrene (opdragelse osv.). Udelt miljø er en restgruppe som omhandler alting der ikke falder i de to andre grupper hvilket inkluderer miljø som søskende ikke har til fælles, tilfældigheder samt målefejl. Et mere passende navn er derfor “everything else“.
Den konceptuelle simpleste løsning til at estimere arveligheden af et træk er at opspore en-æggede tvillinger som ikke er vokset op sammen. I den grad at de er ens kan ikke skyldes delt miljø og må derfor skyldes gener (undtagelsen er miljøet i livmoderen under graviditeten). Man kan derfor estimere arveligheden direkte ved at måle på hvor ens de er. De er ret svære at finde, især nu om dage hvor bortadoptioner ikke er ret normale, men det er lykkedes at finde nogle af dem og forskere har målt alle mulige træk hos dem. Tabellen nedenfor viser resultaterne af det største studie på området.
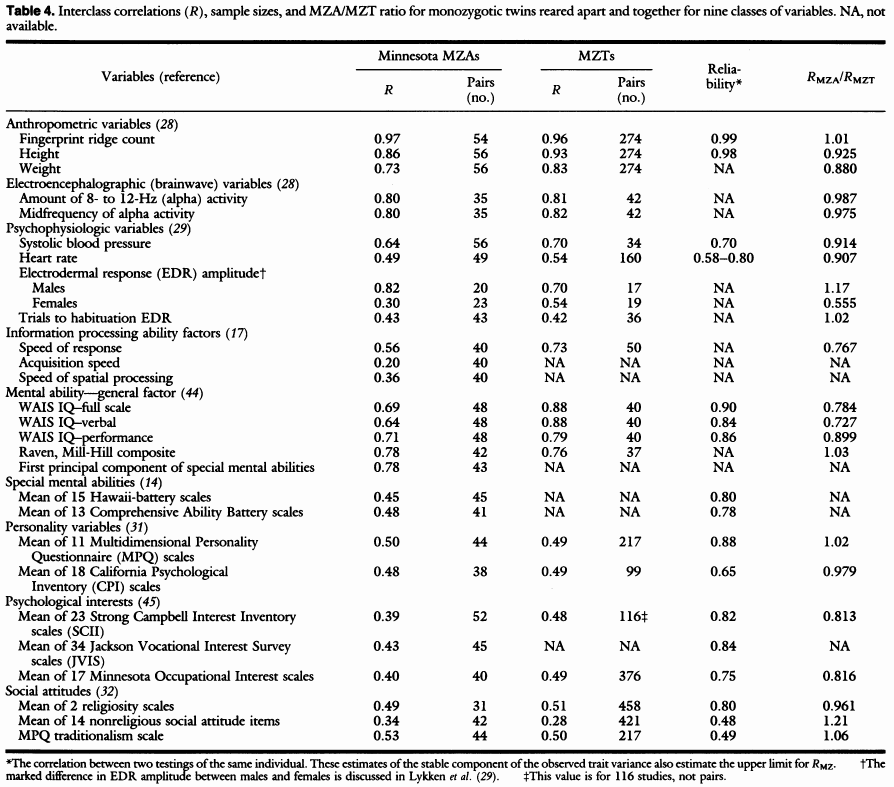
(Kilde: Bouchard, T. J., Lykken, D. T., McGue, M., Segal, N. L., & Tellegen, A. (1990). Sources of human psychological differences: the Minnesota Study of Twins Reared Apart. Science, 250(4978), 223–228. https://doi.org/10.1126/science.2218526)
Her skal man se efter kolonnen R (korrelationen) under MZA (mono-zygostic apart = en-æggede som voksede op uafhængigt). Bemærk at der er relativt få personer i studiet, hvilket skyldes ganske enkelt at det er meget svært at finde den slags personer. Man skal se på det overordnede mønster, som tydeligvis viser at tallene ofte er ret høje. Fx er ensheden for højde og vægt .86 og .73, hvilket betyder at arveligheden for dem er 86% og 73%. Det er tal som stemmer godt overens med senere studier som bruger andre metoder. En stor meta-analyse af studier af BMI fandt en gennemsnitlig arvelighed på 75%.
Siden at man ikke kan finde så mange en-æggede tvillinger som er vokset op hver for sig, så må man bruge andre metoder. En anden relativ simpel metode er at finde normale, ikke-tvilling bortadoptioner og opspore deres biologiske forældre. Da børn og forældre har 50% gener til fælles, så kan man dermed gange deres enshed med 2 og få et estimat for arveligheden. En meta-analyse af adoptivstudier af antisocial adfærd fandt en arvelighed i retning af 31 til 48%, mens at effekten af delt miljø var 5 til 13%. Til sammenligning viste tvillingestudierne at arveligheden var 45% og delt miljø var 12%. Med andre ord, kriminalitet løber i familierne primært af genetiske årsager. Studierne fandt cirka de samme resultater på trods af de brugte forskellige metoder og forskellige datasæt.
Kan man ikke finde adoptivbørn, tvillinger eller ej, så kan man bruge andre metoder. Der er et stort antal forskellige måder at gøre det på, men den simpleste og mest anvendte metode (‘standard tvillingemetoden’) består i at finde data fra begge type af tvillinger og sammenligne dem. Teorien bag det er relativ simpel: begge grupper af tvillinger er vokset op sammen, så de har begge 100% delt miljø til fælles, men en-æggede tvillinger er 100% genetisk ens mens to-æggede kun er 50%. Matematisk set kan man derfor estimere arveligheden ved at udregne forskellen i korrelationerne mellem grupperne og gange med 2. Hvis korrelationen mellem en-æggede er .80 mens den for to-æggede kun er .60, så kan man derfor udregne at arveligheden er 2*(.80 – .60)=.40, dvs. 40%. Delt miljø er derfor 40% (.80 – .40) og den resterende del er i ‘everything else’ kategorien. Metoden anvendes i stor stil og kan historisk set spores tilbage til Galton’s ideer om arvelighed sidst i 1800-tallet. Som eksempel viser figuren nedenfor resultaterne fra en stor meta-analyse af fedme hos børn:

(Kilde: Silventoinen, K., Rokholm, B., Kaprio, undefined J., & Sørensen, T. I. A. (2009). The genetic and environmental influences on childhood obesity: a systematic review of twin and adoption studies. International Journal of Obesity, 34(1), 29–40. https://doi.org/10.1038/ijo.2009.177 Grafen er lavet af os.)
De lodrette linjer viser medianerne som var 74%, 11% og 14%. Altså, ensheden af fedme hos forældre og deres børn skyldes næsten udelukkende genetiske årsager og ikke forældrenes indflydelse. De tre parametre kaldes ofte blot for A (arvelighed), C (delt miljø) og E (udelt miljø/everything else).
Fejlkilder
Der findes en række forskellige måder hvorpå estimaterne fra adfærdsgenetiske studier kan være forkerte. Den simpleste af dem er sampling error, dvs. at gruppen af personer er urepræsentativ på en sådan måde at det påvirker resultaterne. Hvis der fx findes 10,000 tvillinger i Danmark og vi kun har data for 200 af dem, så kunne det være at vi ved en tilfældighed har fundet nogle hvor to-æggede tvillinger er mere ens end de er i hele befolkningen. Det ville forskubbe resultaterne i retning af at delt miljø ser vigtigere ud end det er. Denne type af fejl forskyder (biaser) ikke resultaterne i nogen bestemt retning, og kan reduceres ved at samle mere data og mere repræsentativ data.
Der findes en række andre fejlkilder som er systematiske hvilket vil sige at de påvirker resultaterne i en bestemt retning. De vigtigste af dem bliver gennemgået herunder. En mere udførlig diskussion af disse fejlkilder findes i dette studie.
Målefejl
Målefejl er den simpleste af de systematiske fejlkilder og består ganske enkelt i at vi ikke kan måle noget med 100%s nøjagtighed. Hvis man måler højden på en person to gange indenfor kort tid (fx 1 time, prøv på dig selv!), så får man ofte to lidt forskellige resultater — måske 1-2 cm forskel. Jo mere målefejl der er, jo mindre vil korrelationerne blive fordi tilfældig støj i målingen ikke korrelerer med noget som helst. Målefejl udtrykkes ofte i test-gentest pålideligheden som er korrelationen mellem den samme test givet to gangen indenfor kort tid (test-retest reliability). Hvis vi leger at en- og to-æggede tvillinger korrelerer .90 og .45 for højde, så vil vi estimere arveligheden til at være 90% [2*(.90-.45)], delt miljø til at være 0% og resten til at være 10%. Men hvis vi ikke kan måle højde helt uden målefejl, så ville tallene være mindre. Hvis fx at vores metode til at måle højde har en test-genrest pålidelighed på .90, så ville vi ikke observere tallene .90 og .45 men i stedet tallene .81 og .41 (afrundet). Hvis vi bruger dem til at udregne de samme parametre som før, så får vi i stedet at arveligheden er 81%, delt miljø 0% og resten 19%. Med andre ord har vi underestimeret arveligheden med 9%points fordi vi ikke kunne måle højde uden fejl.
Det er muligt at justere observerede tal for målefejl hvis man ved hvor stor målefejlen er og på den måde undgå denne fejlkilde. Underligt nok gøres det ikke i praksis, så udgivne resultater er systematisk for lave, særligt for træk der er svære at måle eller hvor man har brugt suboptimale metoder. Hvis man fx har målt personlighed med en kort test på kun 10 spørgsmål, så er test-gentest korrelationen på cirka .72. Hvis man bruger sådanne tal til at estimere arveligheden, så er der en relativ stor bias. Hvis vi leger at personlighed er 80% arveligt med tvillingekorrelationer på .80 og .40 og vi har en test-gentest pålidelighed på .72, så ville de observerede korrelationer være på .58 og .29 og vi ville estimere arveligheden til at være 58% i stedet for det rigtige 80%. Denne fejlkilde påvirker ikke estimatet af delt miljø, kun forholdet mellem arvelighed og ‘everything else’.
Særligt tvillingemiljø
En meget omdiskuteret antagelse bag brugen af standardmetoden er at den hviler på hvad der kaldes ens miljø antagelsen (the equal environments assumption). Denne består i at udregningen antager at det miljø som en-æggede tvillinger har til fælles er lige så stærkt som det to-æggede tvillinger har til fælles. Antagelsen kan være forkert hvis andre — inklusive forældrene — behandler en-æggede tvillinger mere ens end to-æggede tvillinger. Det kunne fx være behandlinger baseret på deres udseende, da en-æggede tvillinger ligner hinanden væsentligt mere end to-æggede. I den grad at der er en forskel på miljøet og i den grad at denne forskel gør en forskel, så vil estimaterne blive forskudt i retning af højere arvelighed og mindre delt miljø.
Det er muligt at teste antagelsen på flere måder og det er blevet gjort mange gange. En måde som antagelsen er blevet testet på er ved at se på tvillinger som er blevet misklassificerede: en-æggede som folk troede var to-æggede og omvendt. Hvis det ekstra stærke bånd mellem en-æggede var vigtigt, så ville man forvente at se at misklassificerede to-æggede tvillinger mindede mere om hinanden end korrekt klassificerede to-æggede tvillinger. Nogle resultater ses i figurerne nedenfor:
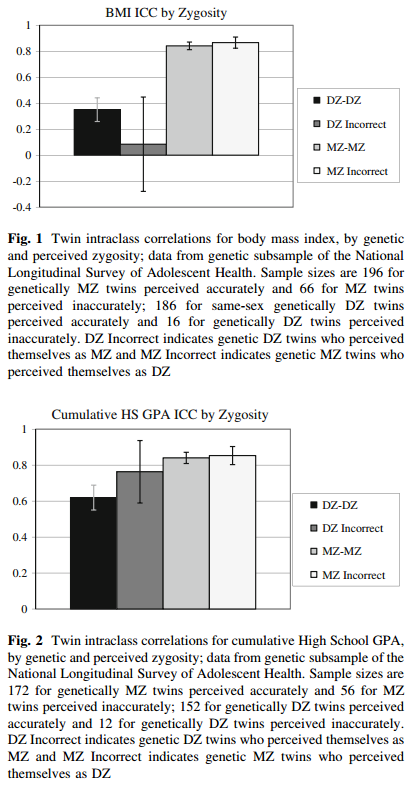
(Kilde: Conley, D., Rauscher, E., Dawes, C., Magnusson, P. K. E., & Siegal, M. L. (2013). Heritability and the Equal Environments Assumption: Evidence from Multiple Samples of Misclassified Twins. Behavior Genetics, 43(5), 415–426. https://doi.org/10.1007/s10519-013-9602-1)
Det er sjældent at man har de rigtige data og nok af dem, så forskerne har set på en række datasæt med diverse metoder for at danne sig et overblik. De to figurer ovenfor viser data for et mindre antal personer. Det kan bemærkes at ensheden for en-æggede (MZ) er næsten ens uanset om de var korrekt klassificerede eller ej. Der er kun data for 12 par af to-æggede (DZ) og derfor er der store fejlbarer på de estimater og de er dermed ikke så sigende. Resultaterne for andre studier fandt cirka de samme resultater.
Generelt set så holder antagelsen næsten i praksis og i den grad at den ikke holder, så er det ikke så vigtigt fordi den slags miljø som en-æggede tvillinger har mere til fælles af kun i ringe grad eller slet ikke påvirker de træk man måler på.
Assortativ parring
Det kommer nok ikke som nogen overraskelse at mennesker ikke vælger partnere tilfældigt. For mange træk lader folk til at vælge partnere som er relativt ens med dem selv, hvilket kaldes for assortativ parring (assortative mating). Det måler man meget simpelt ved at måle træk hos begge partnere i et ægtepar/forhold og korrelere dem. Gør man det, så får man tal som .77 for alder, .75 for religiøsitet, høj for uddannelse, .48 for intelligens, cirka .40 for kriminalitet, cirka .35 for diverse politik og mindre tendensen for personlighed. Der er også tendenser for diverse fysiske træk såsom ørelængde (.40).
Assortativ parring har en bias på estimater fra standard tvillingemetoden. Det skyldes at i den grad at trækkene som partnerne matcher på er arvelige, i den grad er partnerne også genetisk mere ens end gennemsnittet. Den ekstra genetisk enshed vil også afspejle sig i at deres børn bliver mere genetisk ens end normalt for de samme træk. Specifikt gør det at to-æggede tvillinger bliver mere genetisk ens end 50% mens at en-æggede tvillinger allerede er ~100% ens og ikke kan blive mere ens. Hvis fx at to-æggede tvillinger er 60% genetisk ens med hensyn til et træk, så betyder det at forskellen på den genetiske enshed på de to grupper af tvillinger ikke længere er 50%, men i stedet 40% (100-60). Det betyder at når vi ganger forskellen i enshed med to for at estimere arveligheden, så får vi et for lavt tal, 20%point for lavt. Man skal i stedet for gange med 2.4 (100/40).
Normalt tager forskere ikke højde for assortativ parring i deres studier og de udgivede resultater er derfor systematisk for lave. Der findes mere avancerede tvillinge-baserede designs hvor man har mulighed for at undersøge effekten af assortativ parring. Gør man det, så kan man se at det i nogen grad påvirker at arveligheden underestimeres mens at delt miljø overestimeres.
Transgenerationel epigenetik
En mere spekulativ, men populær ide er transgenerationel epigenetik. Vores DNA indeholde mange gener (ca. 20k) og de er ikke alle tændt på en gang. En celle i en nyre har andre aktive gener end en celle i en muskel i en hånd. Hvilke gener der er aktive styres af nogle molekyler som ikke er en del af DNA-koden, men som sidder udenpå. Disse epigenetiske markører kan nok i nogen grad overføres fra forældre til deres børn og de kan også påvirkes af ens miljø. Teoretisk set kunne fx stress hos moderen påvirke hendes epigenetik som derefter gives videre til hendes børn som er blevet bortadopteret. Miljøet for moderen har derfor indirekte påvirket barnets udfald på en sådan måde så det ligner arvelighed. I den grad at dette er tilfældet vil arveligheden derfor blive overestimeret og delt miljø underestimeret.
Der er ikke mange studier af transgenerationel epigenetik hos mennesker, så det er svært at sige hvor stor effekten er, for hvilke træk osv. Evidensen som citeres er nogle gange ret elendig. Fx er det blevet påstået at miljøet på bedstemødre på fars sides skulle påvirke deres børnebørns helbred. Læser man bare en smule efter så ser man dog at forskerne har lavet (mindst) 4 tests og kun 1 af dem havde en p værdi under .05 og kun marginalt. Et sådant resultat kan nemt skyldes chance.
Andre designs
Indtil videre har vi diskuteret tre metoder til at estimere arvelighed m.v.:
- En-æggede tvillinger vokset op hver for sig.
- Bortadoptioner sammenlignet med biologiske/adoptiv forældre eller søskende.
- En-æggede tvillinger sammenlignet med to-æggede tvillinger.
Men det er muligt at bruge mere eller mindre hvilket som helst par af familierelationer til at estimere arveligheden. Man kan også bruge et stort antal forskellige kombinationer samtidig hvis man har den rigtige slags data. Et sådant studie findes fx for Island hvor man har gode arkiver over familier. Personer kan således sammenlignet på kryds og tværs for at estimere arveligheden. Studiet fandt lavere tal end man normalt finder. Fx var estimatet for arveligheden af højde ‘kun’ på 69% mens andre studier som regel finder værdier i området 80-90%. Forskerne konkluderede at standardmetoden havde overestimeret arveligheden. Der er grund til at være skeptisk. Fx fandt et meget stort, avanceret svensk studie af søskende og halvsøskende at standardmetoden ikke havde overestimeret arveligheden, men at delt miljø var overestimeret en smule. [kan ikke finde studiet lige nu]
Et særlig godt design kaldes det udvidede tvillingedesign (the extended twin design). Med det undersøger man ikke blot tvillinger, men også deres børn og mænd/koner samt normale søskende. På den måde er det muligt at tage højde for fx assortativ parring og det ekstra tvillingemiljø. Tabellen nedenfor viser resultaterne fra et stort sådant studie:
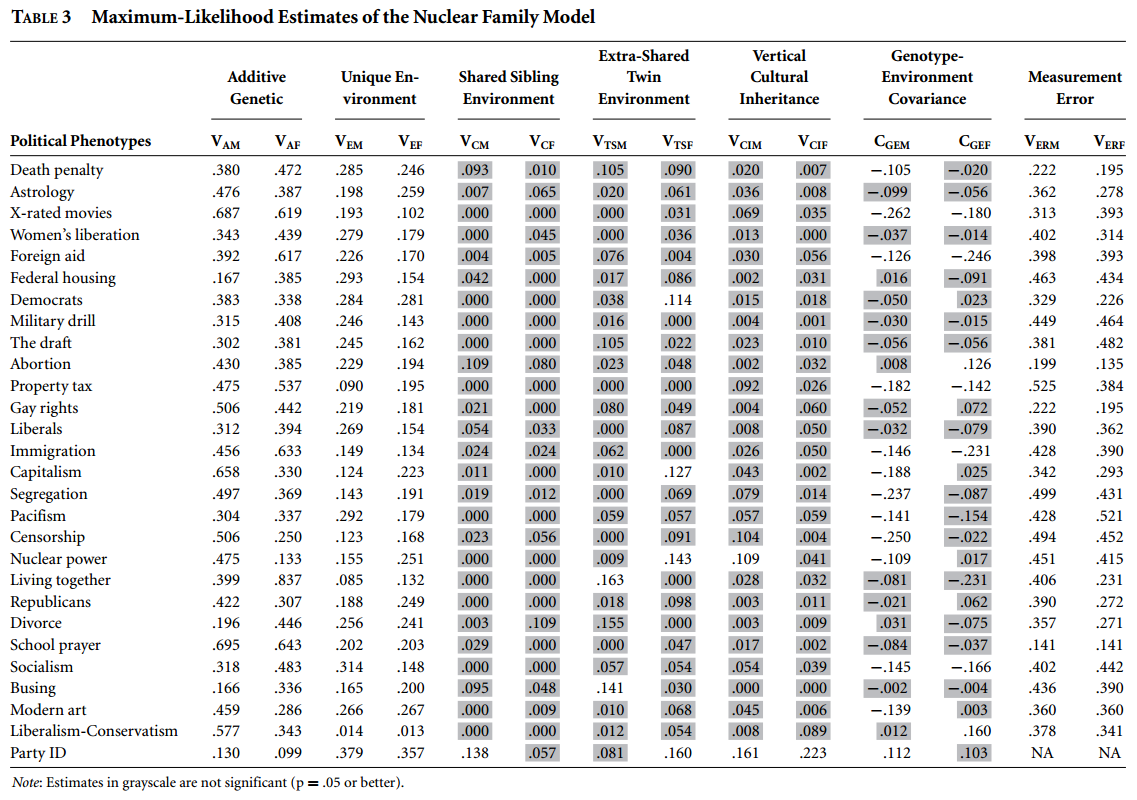
Tal med grå baggrund betyder at værdien ikke er stor nok til at den ikke snarere kan tilskrives en tilfældighed end at der rent faktisk er en effekt større end 0. For langt de fleste politiske holdninger var der ingen detekterbar delt miljø effekt, hvilket inkluderer opdragelse (kolonne shared sibling environment). Kolonnen med extra-shared twin environment omhandler effekter af at være tvillinger vs. at være normale søskende og igen er der stort set ingen effekter.
Hvad viser forskningen generelt?
Adfærdsgenetiske studier er ikke en ny ide og der findes årtier af forskning på emnet. Turkheimer har fundet på tre ‘love’ for feltet som generelt opsummerer resultaterne:
- Alle menneskelige adfærdstræk er arvelige.
- Effekten af at vokse op i den samme familie er mindre end effekten af gener.
- En stor del af variationen i komplekse adfærdstræk skyldes hverken gener eller familiemiljø.
Hertil skal det siges at (3)’eren er kunstigt høj fordi målefejl er inkluderet og mængden af målefejl er ofte relativt stor. Resultaterne for træk som er nemme at måle minder mere om resultaterne for fedme hos børn: arveligheden er ret høj, ofte 60-90%, og delt miljø er relativt lille eller direkte 0.
I 2015 udkom en meget stor meta-analyse af tvillingestudier som fandt en gennemsnitlig arvelighed på 49% på tværs af alle træk og alle datasæt. Figuren nedenfor opsummerer resultaterne:
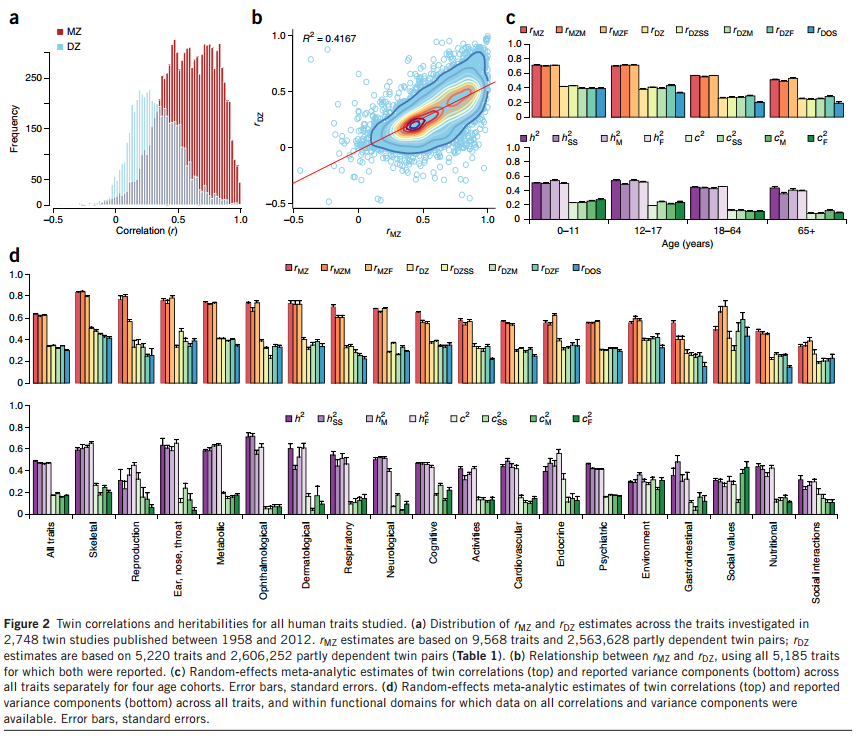
Nederste del af d viser arveligheden på tværs af grupper af træk. Der er relativt store forskelle. Fx er ting relateret til øjnene (ophthalmological) meget arveligt med et gennemsnit på 71%, mens træk relaterede til reproduktion (fx antal børn) ikke var så arveligt igen, i gennemsnit 31%. Det er muligt at selv udforske tallene i detaljer ved at benytte sig af studiets hjemmeside.
DNA-baserede metoder
Da man først begyndte at lave adfærdsgenetiske studier i starten af 1900-tallet havde man ikke adgang til genetiske data. Man kendte ikke engang strukturen af DNA. I de sidste cirka 15 år er det er blevet overkommeligt at lave præcise målinger af menneskers DNA, så er studier begyndt på at bruge DNA data til at studere arvelighed. Det er samme data som man får hvis man køber 23andme‘s test.
En metode bruger det faktum at søskende ikke deler præcis 50% af deres DNA, men at det varierer en smule. Variationen omkring 50% skyldes den måde som genomet nedarves på og sammensættes fra forældrenes DNA. Figuren nedenfor viser fordelingen af genetisk enshed mellem søskende:
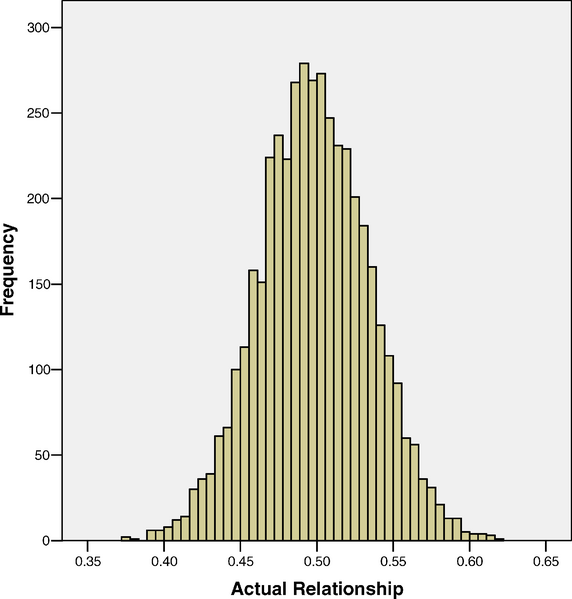
I den grad at genetiske forskelle forklarer variationen i et træk, så vil små forskelle i ensheden blandt søskende afspejle deres enshed i trækket. Altså, søskende som deler fx 55% DNA bør være lidt mere ens i gennemsnit end dem som deler 45%. Hvis man har nok data, så kan man estimere arveligheden direkte på den måde uden at skulle lave de antagelser som laves i fx tvillingestudierne. I studiet ovenfor estimerede man arveligheden for højde til at være 80% hvilket er cirka det samme som resultaterne fra de andre metoder.
Denne type design kan også bruges til at studere raceforskelle i træk ved at se på små forskelle blandt søskende, men det er ikke blevet gjort endnu (læs mere her og her).
En meget anvendt metode som konceptuelt minder om den ovenstående er GREML (også nogle gange ukorrekt kaldet for GCTA). I stedet for at se på søskende, så ser man på personer der ikke er nært beslægtede. Blandt personer som ikke er nært relaterede er der mange som er fjernt relaterede, fx 5. fætre/kusiner. De er derfor en meget lille smule genetisk ens end endnu fjernere slægtninge. Disse små forskelle i genetisk enshed kan bruges til at estimere arveligheden (additiv) af et træk såfremt at man har nok data. Nok data betyder her genomisk data fra nogle tusind personer, hvilket er relativt nemt at finde. Et stort studie med højde fandt at arveligheden kunne estimeres til at være mindst 50%. Fornylig blev et studie udgivet som konkluderede at GREML studier er baseret på nogle tvivlsomme antagelser. I stedet udviklede de en anden lignende metode som gav 40% højere arvelighed for en lang række træk i sammenligning med GREML. GREML og lignende metoder er stadig ret nye, så der kommer nok flere forbedringer indenfor få år.
Den ultimative metode til at finde ud af hvor arveligt et træk er består i at identificere alle de genetiske varianter som forklarer den variation man ser. Det gøres med GWASs (genome-wide association study), som er studier som ser på variation for hele det menneskelige genom og forsøger at relatere dem til forskelle i træk. Det menneskelige genom er omkring 3 milliarder basepar langt, så der er i den grad tale om at lede efter nåle i en høstak. I praksis bruger man i stedet data for relativt normale SNPs (en særlig type simpel variant) som der kun er 0.5 til 10 millioner af. Forskning viser at træk som højde er styret af et meget stort antal varianter (flere tusind, måske 10k) med lille effekt hver. Det gør dem meget svære at finde og man skal bruge et meget stort antal mennesker. I det fornævnte studie af højde brugte man data fra 253k personer. Det gav pote for man fandt ~700 varianter som man kan være rimelig sikker på er relateret til højde, hver med en meget lille effekt (fx at man er 0.1 centimeter højere hvis man har variant A i stedet for B). I et nyere studie af uddannelseslængde analyserede man data fra 294k personer og var i stand til at finde omkring 160 varianter. Såfremt at man bruger den rigtige metode, så tyder simuleringer på at man skal bruge i retning af 1 million personer for at finde de fleste varianter i et komplekst træk som højde.
Ikke alle træk involverer flere tusind varianter med lille effekt. I nogle tilfælde findes der en særlig fejl som har en stor effekt og som nemt kan findes. Det gælder fx for brystcancer hvor variation i generne BRCA1/2 har meget store effekter, så store at folk vælger at præventivt få fjernet deres bryster fordi sandsynligheden for brystcancer er i retning af 50-60% hvis man har en dårlig variant.
Konklusion
For at opsummere:
- Der findes mange forskellige metoder til at studere arveligheden af træk og deres resultater stemmer nogenlunde overens med hinanden. Det gør det meget usandsynligt at det overordnede billede er forkert.
- Variation i næsten alle menneskelige træk kan spores til variation i deres gener.
- I mange tilfælde er betydningen af gener meget større end af miljøet. Det gælder særligt det som kaldes delt miljø, og som er det som medierne næsten ensidigt fokuserer på.
- Adfærdsgenetik er relativt kompliceret og hvis man vil forstå detaljerne, så skal man bruge tid på at læse op på emnet. En stærk baggrund i statistik anbefales. Feltet er under rivende udvikling pga. den store mængde DNA data som er blevet samlet de seneste 10 år.
For at holde denne introduktion kort, så har vi simplificeret nogle ting og sprunget andre over, blandt andet:
- Undertyper af arvelige og miljø effekter: additiv arvelighed (, dominans arvelighed (interaktioner indenfor en lokus) og epistasis arvelighed (interaktions effekter på tværs af lokusser). Derudover genetisk-miljø korrelationer og interaktioner. Disse ting gør diskussionen mere kompliceret. GREML estimerer kun additive effekter og blandt andet derfor er tallene lavere end dem fra familiestudierne.
- Arveligheden af træk kan variere på tværs af grupper, såsom personer af forskellig alder, køn, etnicitet/race og social status.
- Særligt arveligheden af intelligens har været særlig kontroversiel grundet dette træks store vigtighed for mange ting, herunder særligt social ulighed. Derfor er dette træk også det mest velstuderede træk. Arveligheden er høj for voksne i retning af 80% og mindre for børn.
- Som konsekvens af det ovenstående, så viser en række studier også at social ulighed er arveligt i nogen grad, alt efter hvad præcis man måler på. Uddannelse har fx en arvelighed på omkring 40% i Norden.
- Gruppeforskelle er særligt kontroversielle. Det er muligt at finde ud af om de forskelle man ser på tværs af racegrupper er arvelige eller ej, men den slags studier laves sjældent pga. berøringsangst.
Hvis man er mere nysgerrig, så anbefales følgende lærebog:
- Plomin, R., DeFries, J. C., Knopik, V. S., & Neiderhiser, J. M. (2012). Behavioral Genetics (6 edition). New York: Worth Publishers.